Job Lifecycle
Jobs in Sidequest.js go through well-defined states as they progress from creation to completion. Understanding these states helps you monitor job execution and debug issues.
Job States
Jobs progress through the following states:
waiting- Job is queued and waiting to be processedclaimed- Job has been claimed by a worker and is about to startrunning- Job is currently being processedcompleted- Job finished successfullyfailed- Job failed and won't be retried (max attempts reached)canceled- Job was manually canceled
State Transitions
The lifecycle of a job can be visualized as follows:
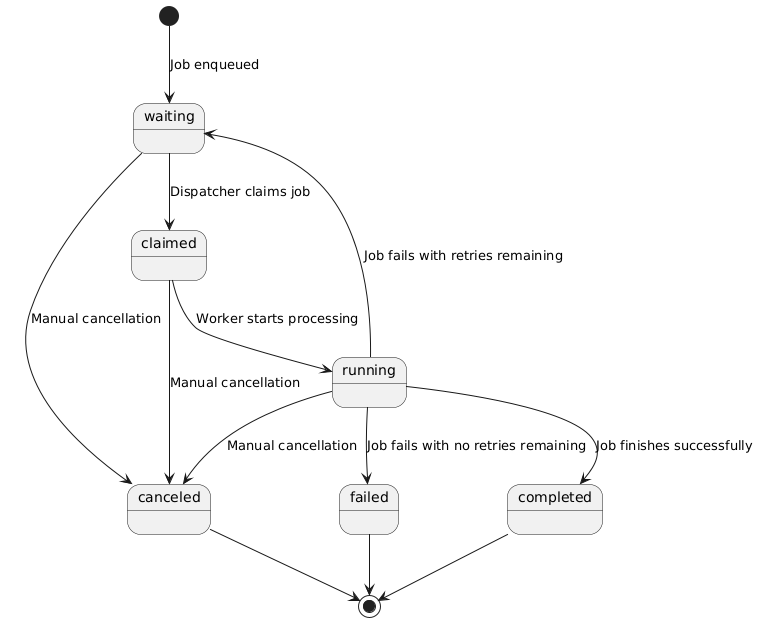
Normal Execution Flow
text
waiting → claimed → running → completed- Creation: Job starts in
waitingstate when enqueued - Claiming: Dispatcher claims the job, moving it to
claimed - Execution: Worker starts processing, job becomes
running - Completion: Job finishes successfully, becomes
completed
Failure and Retry Flow
text
waiting → claimed → running → waiting (retry)
waiting → claimed → running → failed (max attempts)When a job fails but has remaining retry attempts:
- Job returns to
waitingstate with incremented attempt counter - Errors are recorded in the job's
errorsfield - Job waits for any configured retry delay
- Job is eligible to be claimed and run again
When a job fails and has no remaining attempts:
- Job moves to
failedstate permanently - Error information in the job's
errorsfield
Manual Cancellation
text
waiting → canceled
claimed → canceled
running → canceledJobs can be manually canceled at any point before completion:
- Waiting jobs are immediately marked as
canceled - Claimed jobs are marked as
canceledbefore execution an are prevented from running - Running jobs receive a cancellation signal and transition to
canceled
Best Practices
- Set appropriate timeouts: Configure job timeouts to prevent indefinite hanging
- Monitor failed jobs: Set up alerts for jobs that fail permanently. You can poll the backend for failed jobs and notify your team
- Clean up old jobs: Regularly clean up completed and failed jobs to manage storage (Sidequest has a configuration for that - see cleanup guide)
- Use meaningful delays: Don't retry immediately - use exponential backoff for transient failures